LED Graduation Cap

Over the course of my studies at the University of Florida I developed algorithms for subsurface explosive hazard detection. A large problem with developing algorithms on this data is the innate data ambiguity and imprecision. Due to this, a multiple instance learning method was investigated, where learning is done using groups of labeled data instead of singly labeled data points. The proposed algorithm learns multiple target concepts to perform target detection. The sections below highlight my thesis which strictly contains hyperspectral data results due to subsurface explosive hazard data restrictions. This post is strictly a high level overview and more details can be found in the thesis.

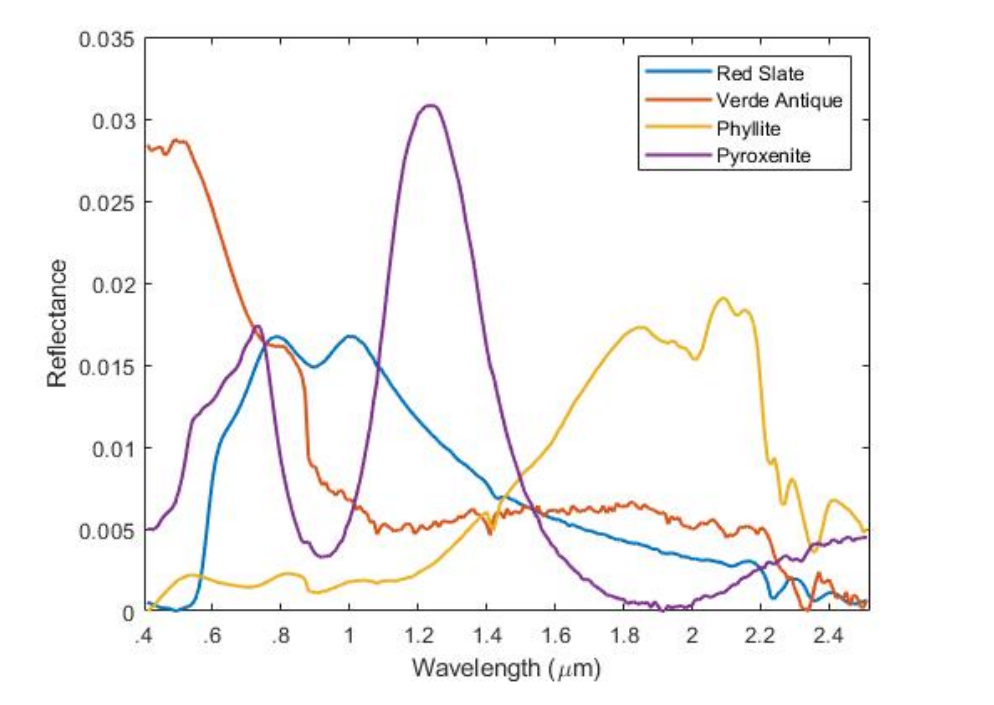
The Multiple Instance Adpative Cosine Estimator and Spectral Match Filter (MI-ACE and MI-SMF) learns a single target signature that maximizes the following objective function.
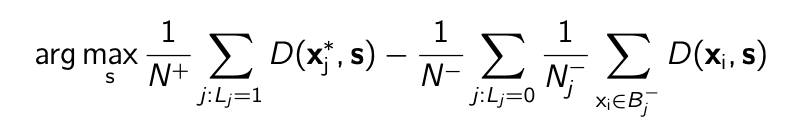
This algorithm assumes the data follows the multiple instance learning framework, where the data has been labeled into two types of groups or bags, positive and negative. A positive bag is defined as a group of data points where at least one of the data points, also known as instances, is an item of interest, known as a target instance(s). A negative bag is defined as a group of data points where all of the data points are pure background, known as non-target instances.
The Multi-target Multiple Instance Adaptive Cosine Estimator and Spectral Matched Filter (Multi-target MI-ACE and Multi-target MI-SMF) algorithm learns a dictionary of target concepts to perform target detection by maximizing the following objective function.
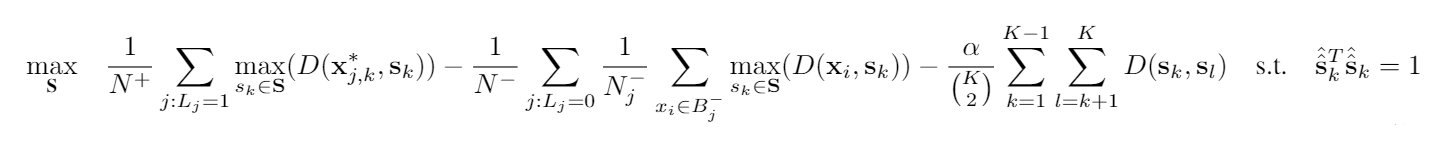
Throughout my studies, many variations were designed and tested. These variations are listed and briefly described below. For more details please view my thesis.
A greedy approach was used during the initialization step of the algorithm. This provided the algorithm with a smaller time complexity than searching every possible combination of target concepts. So instead of trying every possible combination of target concepts to determine which would be the best, only one is selected at a time and then that target concept is assumed moving forward. Then assuming the previously picked target concepts, the algorithm determines the next best target concept to add until the algorithm has initialized K target concepts.

If this was not done and K target concepts were initialized from N possibilities, the complexity would be O(N choose K). For the application of hyperspectral data, N was typically in the 10,000’s and K was typically below ten. Therefor, this complexity was unfeasible, ~10^33 computations.
With the greedy approach, the complexity was reduced to O(NK). By only searching through all N options and initializing the next best target concept. This greedy approach would search all N target concept candidates and select the next best target concept. The next best target concept was determined by testing which one would maximize the objective function. This was done K times, thus the time complexity with the greedy approach is O(NK), ~10^5 computations.
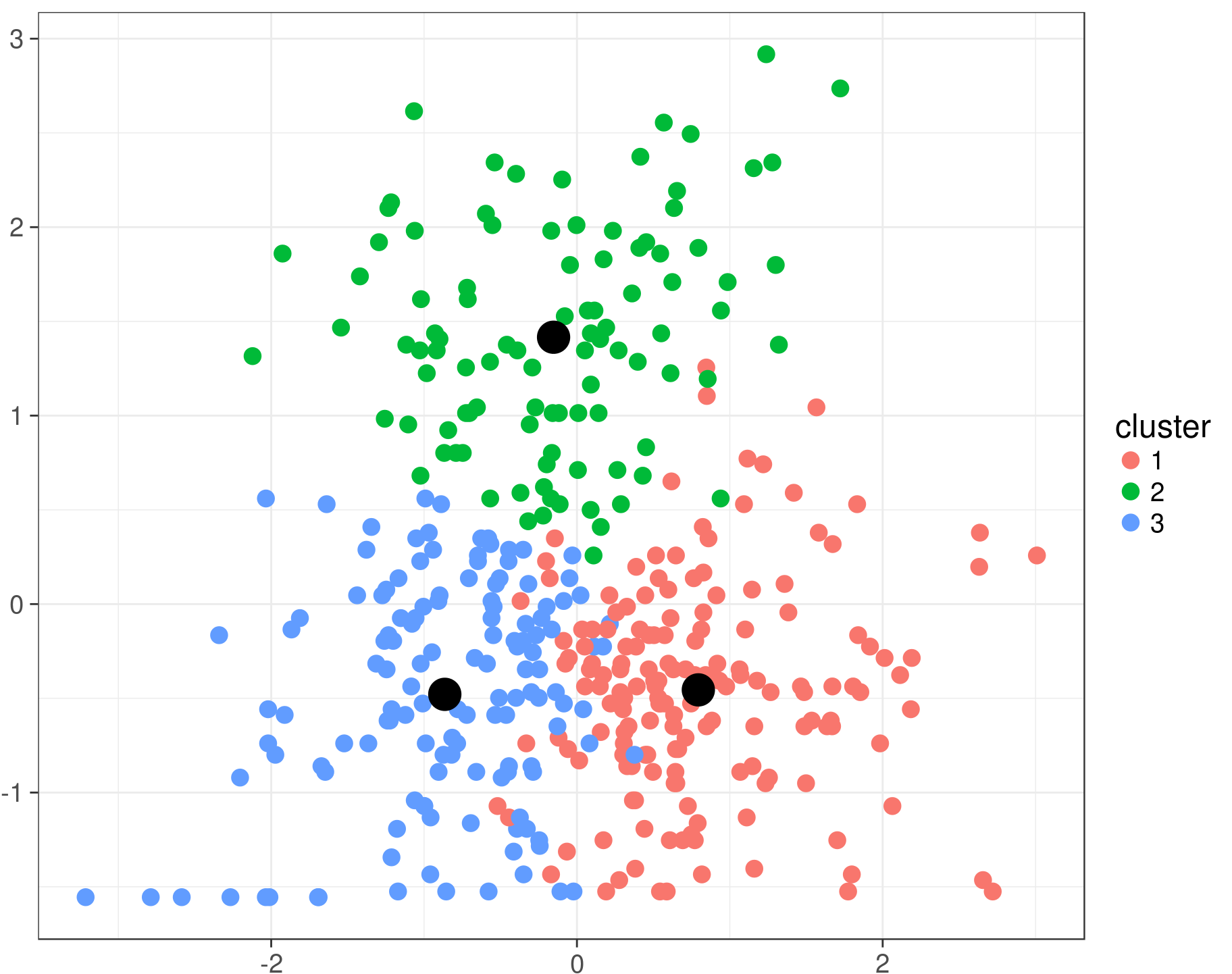
To aid in time complexity and generalization, different clustering approaches were explored during the initialization steps of the algorithm. This reduced the time complexity further by reducing the number of target concept candidates.
Instead of needing to search through N possible candidates (10,000’s), the algorithm would only need to search through C possible candidates (~50). This further reduced time complexity to O(CK) and aided in generalization. The clustering methods explored were k-means clustering, ranked k-means clustering, and multiple instance cluster regression which is based on Gaussian Mixture Models. Of these, on the hyperspectral datasets used, k-means was seen to be the most consistent and outperformed all other approaches during the initialization step.
Furthermore, I explored using weighted approaches to aid in the optimization step. It was noticed that it was difficult for the algorithm to learn different types of target concepts. So by including a weighted term that was related to the similarity of learned target concepts to the target concept it was currently optimizing, the target concepts could be differentiated and more unique. Two weighted approaches were explored, using the ACE or SMF similarity to weight the update term during optimization and using the ACE or SMF similarity passed through a gaussian Kernel to push the similarities to their extreme values of zerp and one.
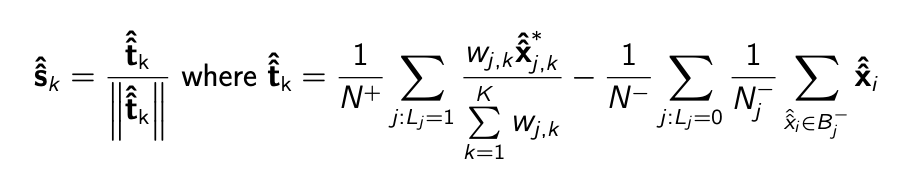
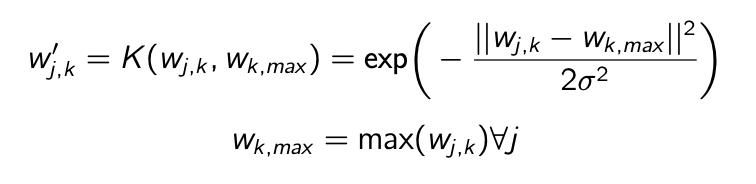
Lastly, a uniqueness term was explored to further encourage target concept uniqueness. By using this, the algorithm’s objective function was discouraged to initialize and optimize any two target concepts in being the same. This term was also configurable with a weight term alpha that helped the user specify how similar target concepts could be. The larger the alpha value specified the more unique the resulting signatures would be.
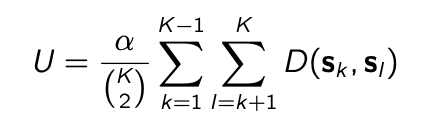
The proposed approaches were found to improve performance on both the simulated hyperspectral dataset as well as the hyperspectral MUUFL Gulfport dataset. The K-Mean’s clustering approach for initialization proved to show the most consistent increase in performance, especially relative to the original single target version of the algorithm. Furthermore, it performed on par with the current state of the art method (MI-HE) while decreasing computational cost significantly.
The thesis PDF can be found here.
The source code is located on the Machine Learning and Sensing Lab’s github repository and will be made public once the corresponding journal paper has been published.
Thanks,
James
Over the course of my studies at the University of Florida I developed algorithms for subsurface explosive hazard detection. A large problem with developing ...
Over the summer of 2018 I had the honor to teach an Introduction to Machine Learning course for UF freshman engineering students.
Q-Learning
Inspired by machine learning, embedded systems, and fun. I teamed up with my classmate Mason Rawson, to make an autonomous turret. Specifically, we made one ...
Objective